A Unified and Controllable Framework for Layered Image Generation with Visual Effects
学习
一、信息
- A Unified and Controllable Framework for Layered Image Generation with Visual Effects
- UC Santa Cruz,Adobe Research
- [2601.15507v2] A Unified and Controllable Framework for Layered Image Generation with Visual Effects
- 以前的方法,只分解 RGBA 的前景层。把前景层视为物体+阴影。支持三种生成模式:给定前景生成背景、给定背景生成前景和t2l。同时提出了一个 dataset:LASAGNA-48K,包含超过 48K 图像三元组的数据集:composite image、clean background、foreground layer with visual effects。

二、方法
2.1 数据
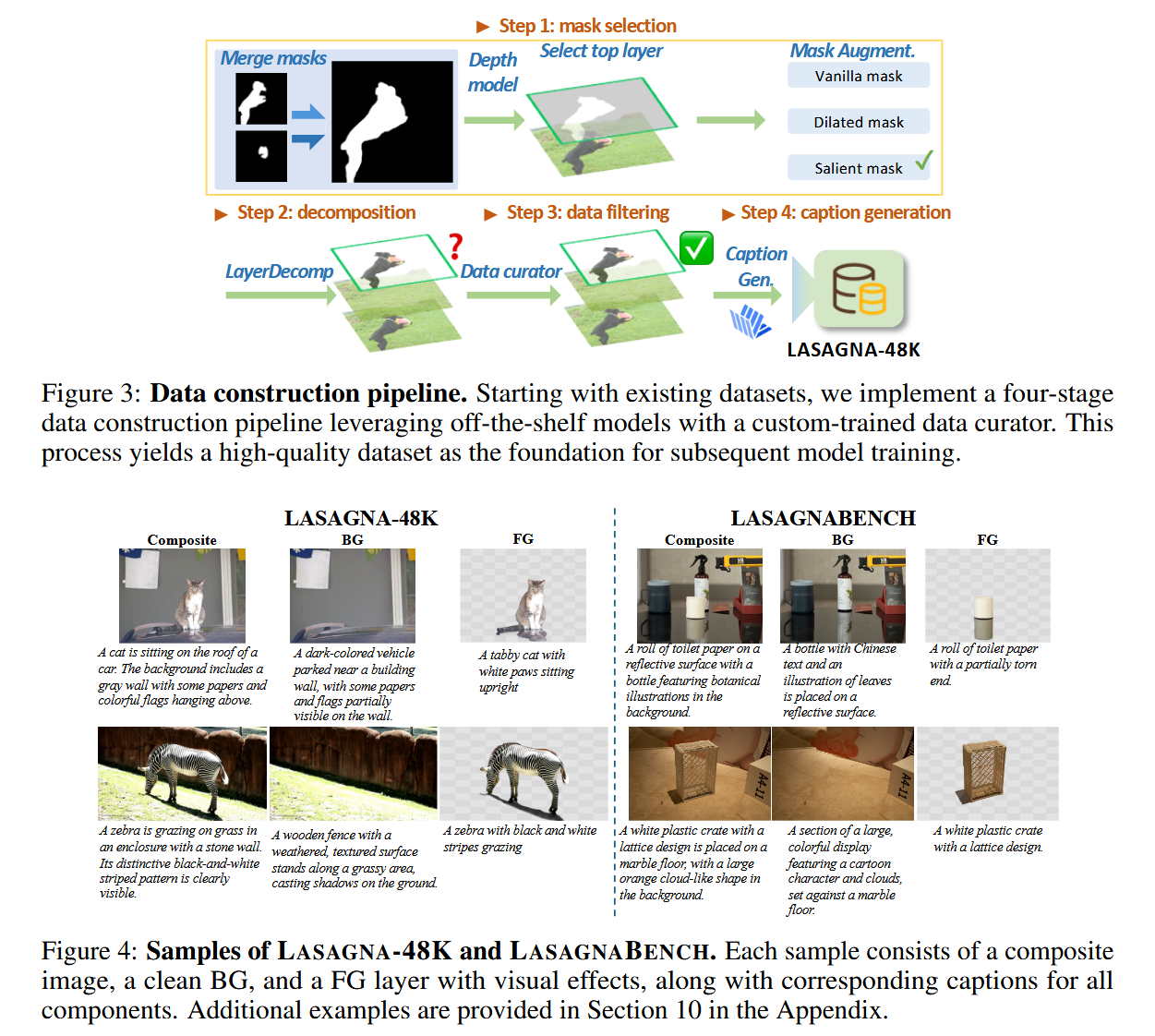
普通 layered dataset 没有“带 visual effects 的前景层”。Lasagna-48K:数据来自 MULAN、COCO 2017、SOBA,最终包括 8K MULAN、39K COCO 和 1K SOBA 样本。
Public datasets
↓
Step 1: Non-occluded mask selection
↓
Step 2: LayerDecomp decomposition
↓
Step 3: VLM-based data filtering / artifact removal
↓
Step 4: Joint captioning
↓
Lasagna-48K triplets:
composite image
clean BG
FG layer with visual effects
captions
2.2 pipeline
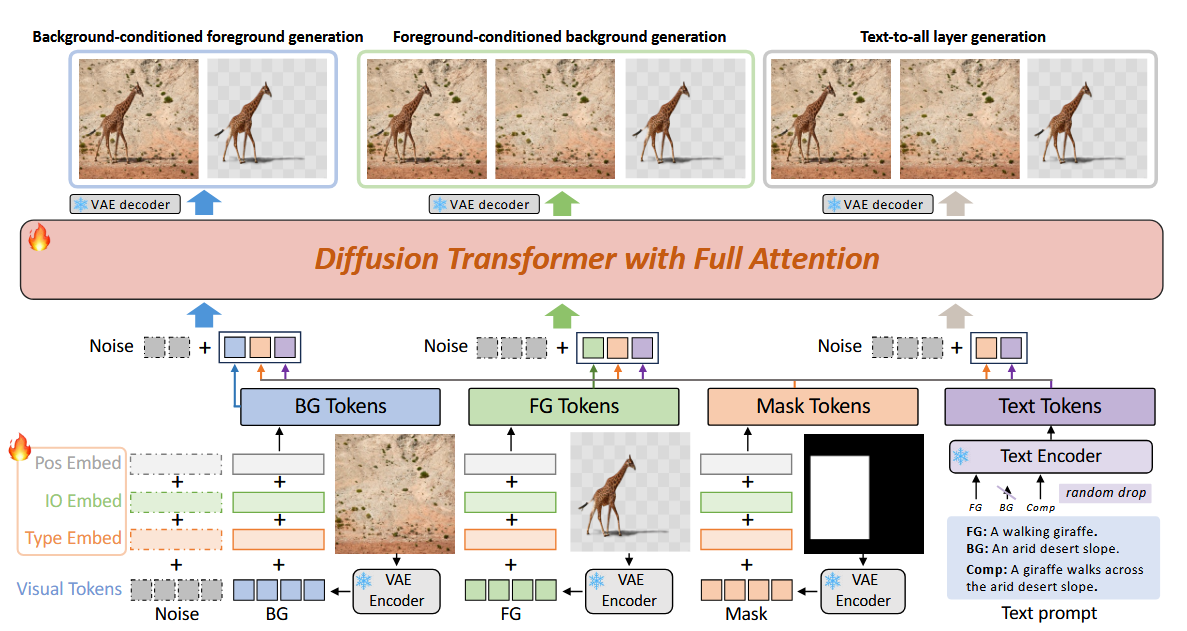
mask、fg 和 bg 当成上下文,和 noisy token 拼接在一起。四类 embedding 注入:

位置编码是3D-RoPE。
具体架构:
- base architecture / backbone:Diffusion Transformer, DiT
- initialization:2B pre-trained DiT model
- text encoder:T5
- image latent:RGBA-VAE,fine-tuned from DiT VAE
- training objective:flow matching