CreatiParser:Generative Image Parsing of Raster Graphic Designs into Editable Layers
一、信息
- title:CreatiParser: Generative Image Parsing of Raster Graphic Designs into Editable Layers
- [2604.19632v1] CreatiParser: Generative Image Parsing of Raster Graphic Designs into Editable Layers
- 机构:中科大
- 文本单独处理,用 Qwen3-VL 学习(GRPO 增强)从图片输出文字协议(json文件),然后渲染出来。主体 diffusion 用 SDXL,三条轨迹,LTA 在同一个空间位置上,让三个分支互相 attention,通过可学习的门控残差加回原 token。
二、方法
2.1 任务定义
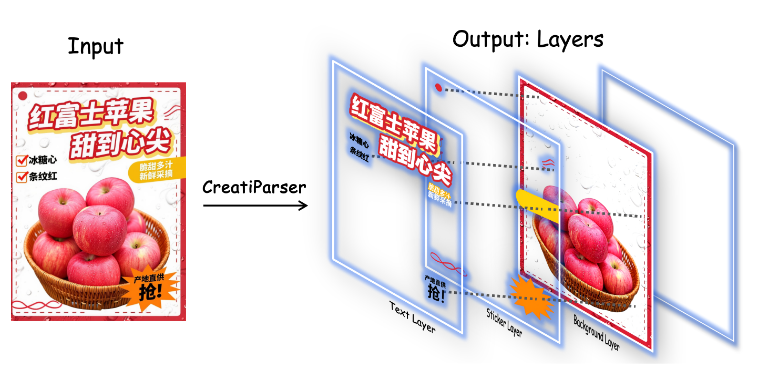
输入:RGB 图 输出:三类可编辑图层:
\[L = \{L_{text}, L_{sticker}, L_{background}\}\]| 输出层 | 类型 | 作用 |
|---|---|---|
| $L_{\text{text}}$ | 可编辑文字层 | 包含所有 typographic elements |
| $L_{\text{sticker}}$ | RGBA 图像 | 非文字前景元素,例如线条、图标、几何形状、装饰元素 |
| $L_{\text{background}}$ | RGB 图像 | 全局背景、纹理、底色、摄影图像等 |

2.2 pipeline
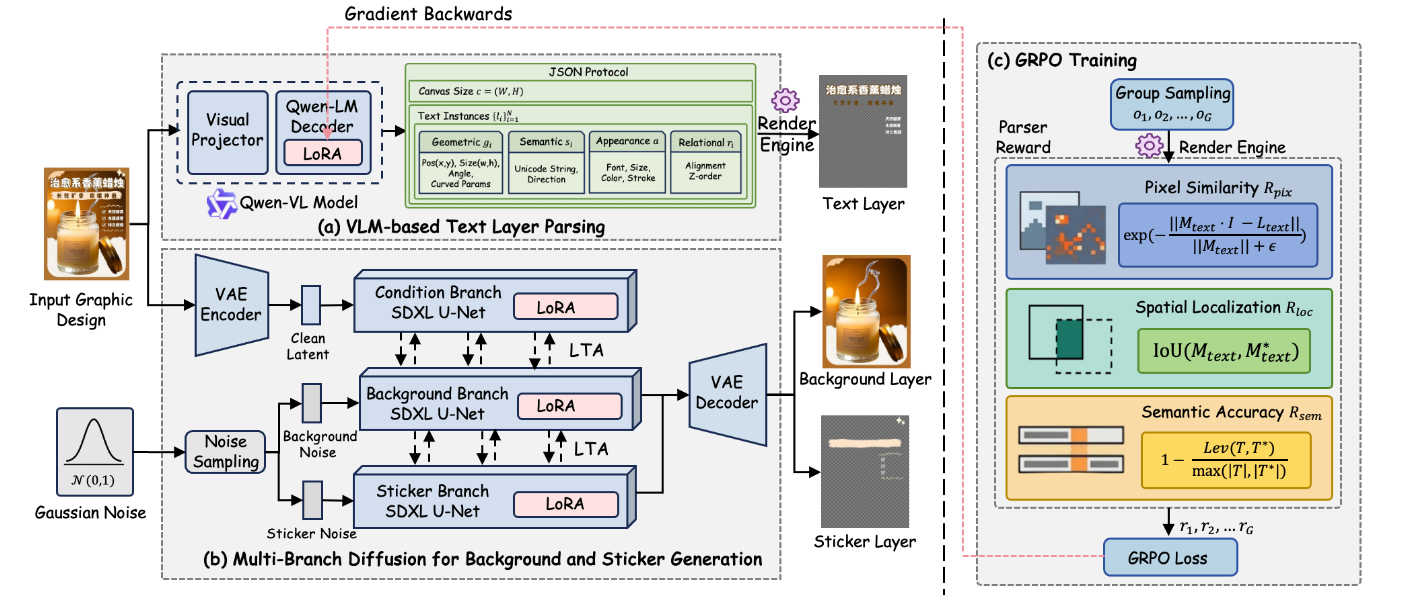
- VLM-based Text Layer Parsing:用 Qwen3-VL + LoRA 从图像预测文本渲染协议 JSON,再用渲染引擎生成文字层。
- Multi-branch Diffusion for Background and Sticker:用三分支 SDXL U-Net 生成背景和贴纸,支持 RGBA 透明图层。
- ParserReward-guided GRPO:只优化 QwenLM 的 LoRA 参数,用奖励函数让文字协议预测更符合像素、位置和语义一致性。
2.2.1 文字部分
论文把文字层表示为 Text Rendering Protocol:
\[P_{text} = \{c, {\ell_i}_{i=1}^{N}\}\]其中:
- $c=(W,H)$:画布尺寸;
- $\ell_i$:第 (i) 个文本实例。
每个文本实例:$\ell_i = (g_i, s_i, a_i, r_i)$ 包括四类属性:
| 属性组 | 内容 |
|---|---|
| Geometry $g_i$ | 位置 $(x,y)$、宽高 $(w,h)$、旋转角 $\theta$、弯曲参数 |
| Semantics $s_i$ | Unicode 文本字符串、阅读方向 |
| Appearance $a_i$ | 字体 ID、字号、颜色、描边、阴影、行高、字距、粗体、斜体、下划线等 |
| Relation $r_i$ | 对齐方式、z-order 层级 |
对于弯曲文字,作者用三次 Bézier 曲线表示路径,并用 $τ$ 表示文字是否沿曲线排列。最后,Qwen3-VL 直接从输入图像预测这个 JSON 协议,再由渲染引擎生成文字层。同时用 GRPO 优化Qwen3-VL 文本协议预测。
2.2.1.1 GRPO refinement
给定输入图 $I$,从 Qwen3-VL 采样 $K$ 个候选协议 ${P^{(k)}}_{k=1}^{K}$,论文默认:K=16,采样使用 temperature sampling,$\tau=0.8$。
每个候选协议都会经过 render engine:
\[L_{text}^{(k)} = \text{Render}(P^{(k)})\]这一步很重要。奖励不是直接看 JSON 文本,而是看 JSON 渲染之后的视觉结果。
每个候选文字层有三个 reward:
- Pixel reward:衡量渲染后的文字层和原图文字区域像素是否接近。
- Localization reward: 衡量文字 mask 位置是否对齐。
- Semantic reward :基于 Levenshtein 编辑距离的文本相似度
其中:
\[\text{Sim}_{edit}(a,b) = 1 - \frac{\text{Lev}(a,b)}{\max(|a|,|b|)}\]总奖励:
\[R_{text} = \lambda_{pix}R_{pix} + \lambda_{loc}R_{loc} + \lambda_{sem}R_{sem}\]组内归一化 advantage :对同一张图的 $K$ 个候选协议,计算 reward 后做 group normalization:
\[A^{(k)} = \frac{r^{(k)} - \mu_r}{\sigma_r + \epsilon}\]GRPO 的核心: 不是训练一个 value model,而是在同一组候选里比较谁更好。
用 clipped objective 更新 LoRA 更新目标类似 PPO:
\[\mathcal{L}_G = -\mathbb{E}\sum_{k=1}^{K} \min\left( \rho^{(k)}A^{(k)}, \ \text{clip}(\rho^{(k)},1-\epsilon_c,1+\epsilon_c)A^{(k)} \right)\]其中:
\[\rho^{(k)} = \frac{\pi_\theta(P^{(k)}|I)}{\pi_{\theta_{old}}(P^{(k)}|I)}\]加 KL 正则:
\[\mathcal{L}_{total} = \mathcal{L}_G + \beta \cdot D_{KL}(\pi_\theta \parallel \pi_{ref})\]论文中 $\epsilon_c=0.2$,$\beta=0.01$,学习率 $10^{-4}$,训练 2000 steps
2.2.2 diffusion
作者以 SDXL 为 backbone,构建三个 U-Net 分支:
| 分支 | 输入 | 核心作用 |
|---|---|---|
| Condition 分支 | 原始设计图 VAE latent | 给另外两个分支提供输入图信息 |
| Background 分支 | 背景层 noisy latent | 生成全局 RGB 背景层 |
| Sticker 分支 | 贴纸层 noisy latent | 生成 RGBA 前景层 |
三个分支拓扑相同,但条件输入不同。每个分支都有独立 LoRA,原始 SDXL 参数冻结,只训练 LoRA。 RGBA latent 用 LayerDiffuse。
2.2.2.1 LTA(Layer Token Attention)
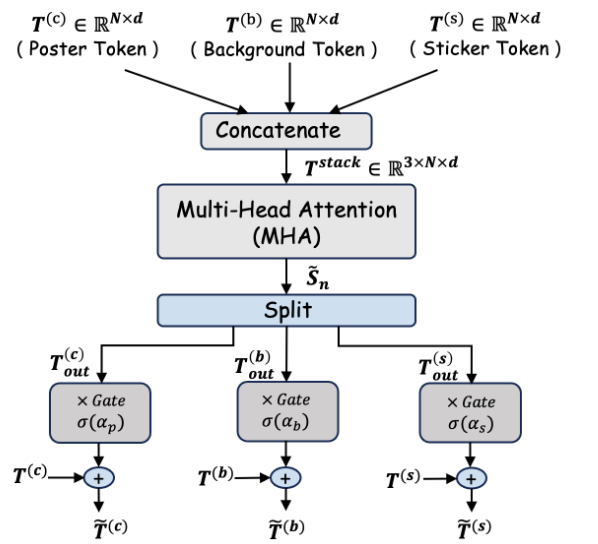 假设三个分支在同一空间位置都有 token:
假设三个分支在同一空间位置都有 token:
作者不是把所有 3N 个 token 全部混合做全局 attention,而是在每个空间位置 n 上,把三个分支的 token 堆起来:
\[S_n = \left[T_n^{(c)}; \; T_n^{(b)}; \; T_n^{(s)}\right] \in \mathbb{R}^{3\times d}\]然后只在这三个分支 token 之间做 attention。也就是说,每个位置只和同一位置的其他分支交流,而不是和全图所有位置交流。最后通过可学习门控融合回原分支。
2.3 数据集和评估
2.3.1 数据集设置
| 数据集 | 用途 | 说明 |
|---|---|---|
| Parser-40K | 训练与测试 | 作者自建,来源于专业设计平台和授权 stock design libraries,原始 PSD 提供 native layer decomposition |
| Crello | zero-shot 测试 | 训练时不用,直接测试跨风格泛化 |
2.3.2 评估指标
评估指标分三类:
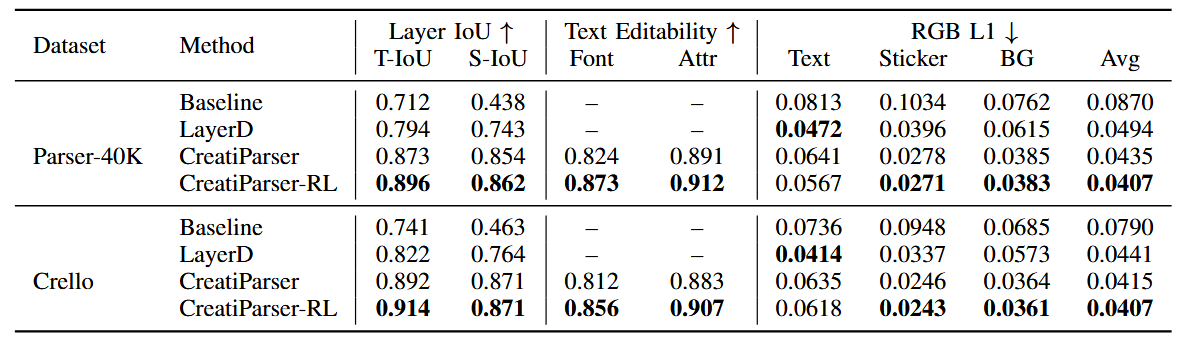
- Layer Reconstruction Accuracy:Text IoU 和 Sticker IoU。
- Text Editability:Font Accuracy 和 Attribute Accuracy。Font 是字体 ID exact match;Attr 是其他外观和关系字段的平均准确率。
- Pixel-Level Reconstruction:分别计算 text、sticker、background 的 RGB L1,以及平均值。
2.3.3 对比方法
- Baseline:Grounded-SAM-2 做 text/sticker segmentation,LaMa 做 background inpainting。
- LayerD:matting-first,再做 background completion。
- 由于不同方法和 Crello 的图层 taxonomy 不一致,作者用 GPT-4V 做自动层类别归一化,并用 200 个样本人工验证,报告总体分类准确率 94.5%。
