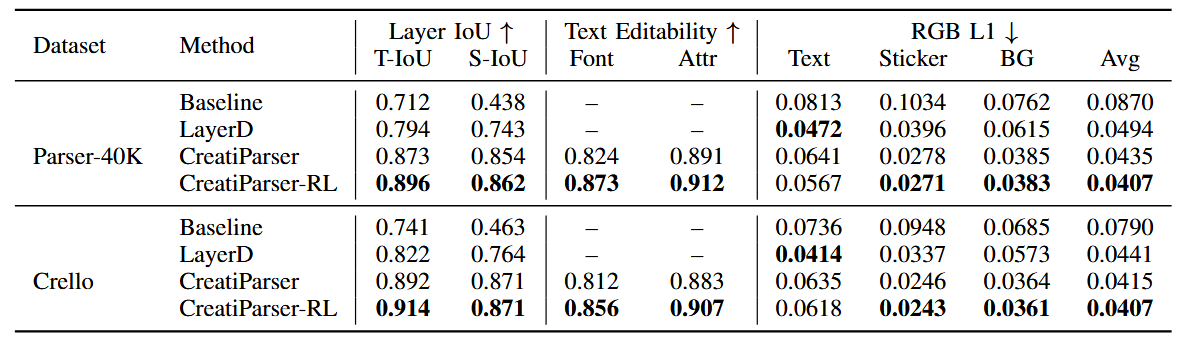
一、PCA类算法
1.1 PCA 的核心目的
PCA,全称 Principal Component Analysis,主成分分析。
它的目标是:
\[\boxed{\text{找几个方向,让数据投影过去以后,保留最多变化信息}}\]
这里的“变化信息”通常用 方差 衡量。方差越大,说明数据在这个方向上越分散,这个方向越能表达数据差异。
在文献中,PCA 被描述为经典的无监督线性降维方法,目标是得到高维数据的紧凑表示,并常用于特征提取和模式识别。
1.2 PCA 推导主线
假设有 $n$ 个样本:
\[x_1,x_2,\dots,x_n\]
每个样本是 $d$ 维列向量:
\[x_i\in\mathbb{R}^{d\times 1}\]
比如一张图片拉平成向量后,每个像素就是一个维度。
1. 求均值
先求所有样本的平均值:
\[\mu=\frac{1}{n}\sum_{i=1}^{n}x_i\]
这个 $\mu$ 也是一个 $d\times 1$ 的列向量。
它表示所有样本的“中心位置”。
2. 中心化
把每个样本减去均值:
\[\tilde{x}_i=x_i-\mu\]
中心化后的样本 $\tilde{x}_i$ 表示:
\[\boxed{\text{第 }i\text{ 个样本相对于平均样本的差异}}\]
如果把所有中心化样本按列拼起来:
\[\tilde{X}=
[\tilde{x}_1,\tilde{x}_2,\dots,\tilde{x}_n]
\in\mathbb{R}^{d\times n}\]
3. 构造散度矩阵 / 协方差矩阵
定义:
\[S=\sum_{i=1}^{n}\tilde{x}_i\tilde{x}_i^T\]
也可以写成:
\[S=\tilde{X}\tilde{X}^T\]
形状是:
\[S\in\mathbb{R}^{d\times d}\]
这个 $S$ 叫 散度矩阵 或 协方差矩阵。
它描述的是:
\[\boxed{\text{数据在各个维度上怎么一起变化}}\]
教程材料中也把
\[S=\sum_i(x_i-\mu)(x_i-\mu)^T\]
称为 covariance matrix 或 scatter matrix,并说明若数据已中心化,则可写成 $S=XX^T$。
4. 投影到一个方向
假设我们找一个方向:
\[u\in\mathbb{R}^{d\times 1}\]
并要求它是单位向量:
\[u^Tu=1\]
一个样本投影到这个方向上:
\[z_i=u^T\tilde{x}_i\]
形状是:
\[(1\times d)(d\times 1)=1\times 1\]
所以 $z_i$ 是一个数字。
它表示:
\[\boxed{\tilde{x}_i\text{ 在方向 }u\text{ 上的坐标}}\]
5. 投影后的总方差
PCA 要让投影后的数据尽量分散,所以看:
\[\sum_{i=1}^{n}z_i^2\]
代入 $z_i=u^T\tilde{x}_i$ 得到:
\[\sum_{i=1}^{n}(u^T\tilde{x}_i)^2\]
展开:
\[(u^T\tilde{x}_i)^2 = u^T\tilde{x}_i\tilde{x}_i^Tu\]
所以:
\[\sum_{i=1}^{n}(u^T\tilde{x}_i)^2
=
\sum_{i=1}^{n}u^T\tilde{x}_i\tilde{x}_i^Tu\]
把 $u$ 提出来:
\[u^T
\left(
\sum_{i=1}^{n}\tilde{x}_i\tilde{x}_i^T
\right)
u\]
而括号里就是 $S$,所以:
\[\sum_{i=1}^{n}z_i^2 = u^TSu\]
于是 PCA 的一维目标变成:
\[\boxed{\max_u u^TSu}\]
并且要求:
\[\boxed{u^Tu=1}\]
教程材料中也说明,$u^TSu$ 可以理解为投影后的方差,也可以理解为中心化数据投影重构后的平方长度。
6. 用拉格朗日乘子求解
现在要解:
\[\max_u u^TSu
\quad
\text{s.t.}
\quad
u^Tu=1\]
构造拉格朗日函数:
\[\mathcal{L}(u,\lambda)
=
u^TSu-\lambda(u^Tu-1)\]
对 $u$ 求导:
\[\frac{\partial \mathcal{L}}{\partial u}
=
2Su-2\lambda u\]
令导数为 0:
\[2Su-2\lambda u=0\]
得到:
\[Su=\lambda u\]
这就是 特征值问题。
7. PCA 的核心结论
\[\boxed{Su=\lambda u}\]
这里:
- $S$:协方差矩阵 / 散度矩阵;
- $u$:特征向量;
- $\lambda$:特征值。
对于单位特征向量 $u$,有:
\[u^TSu
=
u^T(\lambda u)
=
\lambda u^Tu
=
\lambda\]
所以:
\[\boxed{\text{特征值 } \lambda \text{ 就是该方向上保留的方差大小}}\]
因此 PCA 选择:
\[\boxed{S\text{ 最大特征值对应的特征向量}}\]
作为第一主成分方向。
1.3 多个主成分的形式
如果不只要一个方向,而是要 $k$ 个方向:
\[u_1,u_2,\dots,u_k\]
把它们按列拼成矩阵:
\[U=[u_1,u_2,\dots,u_k]
\in\mathbb{R}^{d\times k}\]
要求这些方向两两正交、每个长度为 1:
\[U^TU=I\]
投影:
\[Y=U^T\tilde{X}\]
形状:
\[(k\times d)(d\times n)=k\times n\]
也就是:
\[\boxed{d\text{ 维数据 } \rightarrow k\text{ 维数据}}\]
多个方向上的总方差是:
\[\operatorname{tr}(U^TSU)\]
于是多维 PCA 目标是:
\[\boxed{\max_U \operatorname{tr}(U^TSU),\quad U^TU=I}\]
最优解是:
\[\boxed{U=[q_1,q_2,\dots,q_k]}\]
其中 $q_1,\dots,q_k$ 是 $S$ 最大的 $k$ 个特征值对应的特征向量。
1.4 PCA 的另一种理解:最小重构误差
PCA 也可以从“重构”角度理解。
一个样本投影到低维空间:
\[y_i=U^T\tilde{x}_i\]
再重构回原空间:
\[\hat{x}_i=Uy_i = UU^T\tilde{x}_i\]
也就是说:
\[\tilde{x}_i \approx UU^T\tilde{x}_i\]
PCA 选择的 $U$,既能让投影方差最大,也等价于让重构误差尽量小。
文献中也把 PCA 描述为在最小二乘重构误差意义下获得高维数据的紧凑表示。
1.5 PCA 怎么用于人脸识别:Eigenfaces
Eigenfaces 可以理解为:
\[\boxed{\text{Eigenfaces = PCA 用在人脸图像上}}\]
它把每张人脸图像看成一个高维向量,然后用 PCA 找出人脸图像中最主要的变化方向。
2DPCA 文献中提到,Sirovich 和 Kirby 首先用 PCA 表示人脸图像,认为任意人脸可以近似表示为平均脸加少量 eigenimages 的加权和;Turk 和 Pentland 随后提出了著名的 Eigenfaces 人脸识别方法。
1. 图像向量化
假设一张灰度人脸图像大小是:
\[h\times w\]
像素总数:
\[N=h w\]
把图像拉直成列向量:
\[\Gamma_i\in\mathbb{R}^{N\times 1}\]
比如 $100\times 100$ 的图像:
\[N=10000\]
拉直后:
\[\Gamma_i\in\mathbb{R}^{10000\times 1}\]
2. 求平均脸
有 $M$ 张训练人脸:
\[\Gamma_1,\Gamma_2,\dots,\Gamma_M\]
平均脸:
\[\Psi=\frac{1}{M}\sum_{i=1}^{M}\Gamma_i\]
这里 $\Psi$ 也是一张脸,只不过是平均后的脸。
3. 减去平均脸
每张脸中心化:
\[\Phi_i=\Gamma_i-\Psi\]
$\Phi_i$ 表示:
\[\boxed{\text{第 }i\text{ 张脸相对于平均脸的差异}}\]
4. 组成训练矩阵
把所有中心化人脸按列拼起来:
\[A=[\Phi_1,\Phi_2,\dots,\Phi_M]\]
形状:
\[A\in\mathbb{R}^{N\times M}\]
其中:
- $N$:每张图像的像素数;
- $M$:训练图像数量。
通常:
\[N\gg M\]
比如:
\[N=10000,\quad M=100\]
5. 正常 PCA 要求协方差矩阵
理论上要构造:
\[C=AA^T\]
形状:
\[AA^T = (N\times M)(M\times N) = N\times N\]
如果 $N=10000$,那么:
\[C\in\mathbb{R}^{10000\times 10000}\]
太大。
文献也指出,PCA 人脸识别需要先把二维人脸矩阵变成一维图像向量,这会导致很高维的向量空间;由于协方差矩阵大且训练样本相对少,准确估计协方差矩阵会很困难。
1.6 Eigenfaces 的小矩阵技巧
真正想求的是:
\[AA^Tu=\lambda u\]
其中:
\[u\in\mathbb{R}^{N\times 1}\]
这个 $u$ 可以 reshape 回一张图像,所以叫 eigenface,特征脸。
但 $AA^T$ 太大,于是改求小矩阵:
\[A^TA\]
形状:
\[A^TA = (M\times N)(N\times M) = M\times M\]
如果 $M=100$,那么只需要分解 $100\times 100$ 的小矩阵。
关键推导
先求:
\[A^TA v=\lambda v\]
其中:
\[v\in\mathbb{R}^{M\times 1}\]
两边左乘 $A$:
\[A(A^TA v)=A(\lambda v)\]
左边变成:
\[AA^T(Av)\]
右边变成:
\[\lambda(Av)\]
所以:
\[AA^T(Av)=\lambda(Av)\]
因此:
\[\boxed{u=Av}\]
就是大矩阵 $AA^T$ 的特征向量。
这就是 Eigenfaces 最重要的计算技巧:
\[\boxed{A^TAv=\lambda v \Rightarrow AA^T(Av)=\lambda(Av)}\]
文献中也提到,Eigenfaces 的特征向量可以通过 SVD 等技术高效计算,从而避免直接生成巨大协方差矩阵。
1.7 人脸如何用 Eigenfaces 表示?
取前 $K$ 个特征脸:
\[u_1,u_2,\dots,u_K\]
把它们组成:
\[U=[u_1,u_2,\dots,u_K]
\in\mathbb{R}^{N\times K}\]
对一张新脸 $\Gamma$,先减平均脸:
\[\Phi=\Gamma-\Psi\]
再投影:
\[\Omega=U^T\Phi\]
形状:
\[(K\times N)(N\times 1)=K\times 1\]
所以:
\[\Omega=
\begin{bmatrix}
\omega_1\\
\omega_2\\
\vdots\\
\omega_K
\end{bmatrix}\]
这就是这张脸的低维表示。
原来一张脸需要 $N$ 个像素表示,现在只需要 $K$ 个权重表示。
1.8 人脸重构公式
因为:
\[\Omega=U^T\Phi\]
所以可以近似重构:
\[\Phi\approx U\Omega\]
加回平均脸:
\[\boxed{\Gamma\approx \Psi+U\Omega}\]
展开写:
\[\boxed{\Gamma\approx \Psi+ \sum_{k=1}^{K}\omega_k u_k}\]
这句话是 Eigenfaces 的核心直观解释:
\[\boxed{\text{一张人脸 } \approx \text{平均脸} + \text{若干特征脸的加权组合}}\]
2DPCA 论文也指出,在 Eigenfaces 方法中,主成分和特征向量可以组合起来重构人脸图像。
1.9 人脸识别流程
训练阶段:
- 把每张训练人脸拉成向量 $\Gamma_i$;
- 求平均脸 $\Psi$;
- 得到中心化人脸 $\Phi_i=\Gamma_i-\Psi$;
- 组成矩阵 $A=[\Phi_1,\dots,\Phi_M]$;
- 求小矩阵 $A^TA$ 的特征向量 $v_k$;
- 得到真正特征脸:
\[u_k=Av_k\]
- 取前 $K$ 个特征脸;
- 每张训练脸投影成权重向量:
\[\Omega_i=U^T\Phi_i\]
测试阶段:
- 新脸 $\Gamma_{\text{test}}$ 减平均脸:
\[\Phi_{\text{test}}=\Gamma_{\text{test}}-\Psi\]
- 投影成权重:
\[\Omega_{\text{test}}=U^T\Phi_{\text{test}}\]
- 和训练集中每个人脸的权重向量比较距离:
\[\|\Omega_{\text{test}}-\Omega_i\|\]
- 找最近的那个训练样本,作为识别结果。
这就是最近邻分类:
\[\boxed{\text{在低维特征脸空间中找最像的脸}}\]
2DPCA 文献在比较 PCA/Eigenfaces 和 2DPCA 时也说明,PCA/Eigenfaces 使用普通欧氏距离进行最近邻分类。
1.10 延伸
1.10.1 2DPCA
\[\boxed{\text{PCA 拉直图像;2DPCA 不拉直图像}}\]
\[A\in\mathbb{R}^{m\times n},\quad X\in\mathbb{R}^{n\times 1}\]
\[Y=AX\in\mathbb{R}^{m\times 1}\]
\[G_t=\frac{1}{M}\sum_j(A_j-\bar{A})^T(A_j-\bar{A})\]
\[J(X)=X^TG_tX\]
\[G_tX=\lambda X\]
1.10.2 GLRAM
\[\boxed{\text{2DPCA 只右乘;GLRAM 左右都乘}}\]
\[A_i\approx LM_iR^T\]
\[M_i=L^TA_iR\]
\[\min\sum_i\|A_i-LM_iR^T\|_F^2\]
等价于:
\[\max\sum_i\|L^TA_iR\|_F^2\]
1.10.3 FDA
\[\boxed{\text{PCA 看方差;FDA 看类别}}\]
\[S_B=\text{类间散度}\]
\[S_W=\text{类内散度}\]
\[\max_u
\frac{u^TS_Bu}{u^TS_Wu}\]
\[S_Bu=\lambda S_Wu\]
1.10.4 KFDA
\[\boxed{\text{KFDA = 在高维核空间里做 FDA}}\]
\[u\rightarrow \Phi(X)\theta\]
\[\frac{u^TS_Bu}{u^TS_Wu}
\rightarrow
\frac{\theta^TM\theta}{\theta^TN\theta}\]
\[M\theta=\lambda N\theta\]
二、线性降维
从 PCA/Eigenfaces → LDA/Fisherfaces → MMC → NLDA/OLDA → LPP/MFA → RI $(L_{2,1})$ 鲁棒版本
核心问题都是:
\[x\in \mathbb{R}^m \quad \xrightarrow[]{y=U^T x}\quad y\in \mathbb{R}^d,\quad d\ll m\]
目标是在低维空间里保留对分类有用的信息,去掉光照、表情、姿态、噪声、异常值等无关变化。
2.1 总体知识结构
四篇文献可以这样串起来:
| 方法 |
是否用类别标签 |
优化目标 |
典型问题 |
| PCA / Eigenfaces |
否 |
最大化总体方差 |
保留光照等无关变化 |
| LDA / Fisherfaces |
是 |
类间散度大、类内散度小 |
小样本时 $S_W$ 奇异 |
| MMC |
是 |
最大化平均类间 margin |
避免直接求 $S_W^{-1}$ |
| NLDA / OLDA |
是 |
在零空间或正交空间做判别 |
解决欠采样奇异性 |
| LPP / MFA |
LPP 无监督,MFA 有监督 |
保持局部流形/边缘结构 |
对异常值敏感 |
| RI-PCA/LDA/LPP/MFA |
视方法而定 |
用 $L_{2,1}$ 替代 $L_2$ 度量 |
提高鲁棒性 |
Eigenfaces vs Fisherfaces 论文的核心观点是:PCA 最大化总散度,但这些散度可能主要来自光照和表情,而不是身份差异;Fisherfaces 使用类别信息,试图保留身份差异并压制类内变化。论文还指出,同一人脸在固定姿态、不同光照下,理想 Lambertian 情况会落在 3D 线性子空间中,但真实人脸会受阴影、镜面反射、表情影响而偏离该子空间。
2.2 统一符号
设训练样本为
\[X=\{x_1,x_2,\dots,x_N\},\quad x_i\in\mathbb{R}^m\]
共有 $c$ 个类别,第 $i$ 类为 $X_i$,样本数为 $N_i$。
全局均值:
\[\mu=\frac{1}{N}\sum_{k=1}^{N}x_k\]
第 $i$ 类均值:
\[\mu_i=\frac{1}{N_i}\sum_{x_k\in X_i}x_k\]
低维投影:
\[y_k=U^T x_k,\quad U\in \mathbb{R}^{m\times d}\]
2.3PCA / Eigenfaces
2.3.1 PCA 的直观目标
PCA 不使用类别标签,只关心所有样本整体的变化方向。它希望找到投影矩阵 $U$,使投影后样本方差最大。
总散度矩阵:
\[S_T=\sum_{k=1}^{N}(x_k-\mu)(x_k-\mu)^T\]
投影后总散度为:
\[U^T S_T U\]
PCA 目标:
\[U_{\text{PCA}} = \arg\max_U |U^T S_T U|\]
若只取一个方向 $u$,问题变成:
\[\max_{u} u^T S_T u \quad \text{s.t.}\quad u^T u=1\]
2.3.2 PCA 公式推导
构造拉格朗日函数:
\[\mathcal{L}(u,\lambda) = u^T S_T u-\lambda(u^Tu-1)\]
对 $u$ 求导:
\[\frac{\partial \mathcal{L}}{\partial u} = 2S_Tu-2\lambda u=0\]
得到:
\[S_Tu=\lambda u\]
所以 PCA 的投影方向就是 $S_T$ 的特征向量,取最大特征值对应的前 $d$ 个方向。
在 Eigenfaces 中,每张人脸图像被看作一个高维向量,PCA 得到的特征向量仍然具有图像维度,因此可视化后称为 eigenfaces。论文中也指出,若 PCA 维度取到训练样本数附近,Eigenface 方法会接近直接相关匹配。
3.3 PCA 的局限
PCA 最大化的是总散度:
\[S_T=S_B+S_W\]
其中:
- $S_B$:类间散度,有利于分类;
- $S_W$:类内散度,通常是不希望保留的变化。
问题在于 PCA 不区分这两者。光照、表情、姿态变化可能导致很大的类内散度,因此 PCA 可能优先保留这些方向,而不是保留身份判别方向。Eigenfaces 论文明确指出,PCA 对重构是最优的,但不一定对判别最优。
2.4 LDA / Fisherfaces
2.4.1 LDA 的目标
LDA 使用类别标签。它希望:
\[\text{类间距离大,类内距离小}\]
定义类间散度:
\[S_B=\sum_{i=1}^{c}N_i(\mu_i-\mu)(\mu_i-\mu)^T\]
定义类内散度:
\[S_W=\sum_{i=1}^{c}\sum_{x_k\in X_i}(x_k-\mu_i)(x_k-\mu_i)^T\]
LDA 的经典目标是 Fisher 准则:
\[J(U)=\frac{|U^T S_B U|}{|U^T S_W U|}\]
对于单个投影方向 $u$:
\[J(u)=\frac{u^T S_B u}{u^T S_W u}\]
Eigenfaces vs Fisherfaces 论文中正是用这个准则来构造 Fisherfaces,并指出最大可得判别维数不超过 $c-1$。
2.4.2 LDA 单方向推导
令:
\[J(u)=\frac{u^T S_B u}{u^T S_W u}\]
等价于约束优化:
\[\max_u u^T S_B u \quad \text{s.t.}\quad u^T S_W u=1\]
构造拉格朗日函数:
\[\mathcal{L}(u,\lambda) = u^T S_B u-\lambda(u^T S_W u-1)\]
对 $u$ 求导:
\[2S_Bu-2\lambda S_Wu=0\]
得到广义特征值问题:
\[S_Bu=\lambda S_Wu\]
若 $S_W$ 可逆,则:
\[S_W^{-1}S_Bu=\lambda u\]
所以 LDA 取 $S_W^{-1}S_B$ 最大特征值对应的方向。
2.4.3 多维 LDA
对多个方向 $U=[u_1,\dots,u_d]$,目标为:
\[U_{\text{LDA}} = \arg\max_U \frac{|U^T S_B U|}{|U^T S_W U|}\]
解仍来自广义特征值问题:
\[S_B u_i=\lambda_i S_W u_i\]
取最大的 $d$ 个广义特征值对应的特征向量。
由于
\[\operatorname{rank}(S_B)\le c-1\]
所以 LDA 最多只能得到 $c-1$ 个有效判别方向。
2.4.4 Fisherfaces:PCA + LDA
在人脸识别中,经常有:
\[m \gg N\]
也就是图像维度远大于训练样本数。此时:
\[\operatorname{rank}(S_W)\le N-c\]
因此 $S_W$ 奇异,无法直接求 $S_W^{-1}$。
Fisherfaces 的解决方法是:
- 先用 PCA 降到 $N-c$ 维;
- 再在该子空间中做 LDA,降到 $c-1$ 维。
公式为:
\[U_{\text{opt}}^T = U_{\text{LDA}}^T U_{\text{PCA}}^T\]
更具体地:
\[U_{\text{PCA}} = \arg\max_U |U^T S_T U|\]
\[U_{\text{LDA}} = \arg\max_U \frac{|U^T U_{\text{PCA}}^T S_B U_{\text{PCA}} U|}{|U^T U_{\text{PCA}}^T S_W U_{\text{PCA}} U|}\]
Fisherfaces 论文指出,这样做的目的就是先把维度降到 $N-c$,使之后的类内散度矩阵不再奇异,再执行标准 LDA。
2.5 Lambertian 线性子空间模型
这部分解释为什么人脸光照变化可以被线性子空间近似。
对 Lambertian 表面上一点 $p$,图像强度为:
\[E(p)=a(p)n(p)^T s\]
其中:
- $a(p)$:反照率;
- $n(p)\in\mathbb{R}^3$:表面法向量;
- $s\in\mathbb{R}^3$:光照方向与强度。
因为 $E(p)$ 对 $s$ 是线性的,所以整张图像也可以写成:
\[I = B s\]
其中 $B$ 由表面法向和反照率决定。因此固定姿态下,同一张脸在不同光照下的图像理论上位于一个 3D 线性子空间中。Eigenfaces vs Fisherfaces 论文正是基于这一观察来解释线性子空间方法和 Fisherfaces 的动机。
但真实情况有阴影、表情、镜面反射,因此实际图像不会完全落在 3D 子空间中。Fisherfaces 的思想是学习一个投影,使这些类内变化被压制,同时保留身份差异。
2.6 MMC:Maximum Margin Criterion
2.6.1 MMC 的基本思想
MMC 的动机是:LDA 需要处理
\[S_W^{-1}S_B\]
当 $S_W$ 奇异时不稳定。MMC 改用「差值型」准则:
\[S_B-S_W\]
避免直接求 $S_W^{-1}$。
MMC 论文指出,MMC 几何上最大化的是类间平均 margin,并且相比 PCA 更能表示类别可分性;它还可以通过不同约束与 LDA 建立联系。
6.2 MMC 的 margin 推导
设第 $i$ 类均值为 $m_i$,类内散布度为 $s_i$。两个类别之间的 margin 定义为:
\[d_{ij} = |m_i-m_j|^2-s_i-s_j\]
含义:
-
| $ |
m_i-m_j |
^2$:类中心距离,越大越好; |
- $s_i+s_j$:两个类自身扩散程度,越小越好。
总体 MMC 是所有类别对 margin 的加权和:
\[J = \sum_{i}\sum_{j}p_i p_j d_{ij}\]
展开:
\[J = \sum_i\sum_j p_i p_j |m_i-m_j|^2 - \sum_i\sum_j p_i p_j(s_i+s_j)\]
第一项可以化为类间散度:
\[\sum_i\sum_j p_i p_j |m_i-m_j|^2 \propto \operatorname{tr}(S_B)\]
第二项可以化为类内散度:
\[\sum_i\sum_j p_i p_j(s_i+s_j) \propto \operatorname{tr}(S_W)\]
所以:
\[J = \operatorname{tr}(S_B)-\operatorname{tr}(S_W) = \operatorname{tr}(S_B-S_W)\]
投影后:
\[J(U) = \operatorname{tr}\left(U^T(S_B-S_W)U\right)\]
2.6.3 MMC 的特征值推导
约束:
\[U^T U=I\]
单方向时:
\[\max_u u^T(S_B-S_W)u \quad \text{s.t.}\quad u^Tu=1\]
拉格朗日函数:
\[\mathcal{L}(u,\lambda) = u^T(S_B-S_W)u-\lambda(u^Tu-1)\]
求导:
\[2(S_B-S_W)u-2\lambda u=0\]
得到:
\[(S_B-S_W)u=\lambda u\]
所以 MMC 取 $S_B-S_W$ 的较大特征值对应的特征向量。通常只保留正特征值方向,因为:
\[\lambda>0\]
表示该方向上类间分离大于类内扩散。
MMC 论文指出,这种方法不需要计算 $S_W^{-1}$,因此可避开小样本问题;并且在线性特征提取部分,最优解由 $S_B-S_W$ 的特征向量给出。
2.6.4 MMC 与 LDA 的关系
LDA 是比值型:
\[J_{\text{LDA}}(U) = \frac{|U^T S_B U|}{|U^T S_W U|}\]
MMC 是差值型:
\[J_{\text{MMC}}(U) = \operatorname{tr}\left(U^T(S_B-S_W)U\right)\]
二者目标相似:都是希望 $S_B$ 大、$S_W$ 小。
区别是:
- LDA 需要处理 $S_W^{-1}$,小样本时不稳定;
- MMC 不需要求逆,直接做普通特征分解;
- MMC 可以丢弃负特征值方向,因此可能得到更低维但仍有判别力的子空间。
2.7 NLDA:Null Space LDA
2.7.1 为什么需要 NLDA
当 $S_W$ 奇异时,存在一些方向 $u$ 使得:
\[u^T S_W u=0\]
这表示在这些方向上,同一类样本被压缩到一起,即类内散度为 0。若同时:
\[u^T S_B u>0\]
则这些方向对分类非常有用。
NLDA 的目标:
\[G = \arg\max_{G^T S_W G=0} \operatorname{tr}(G^T S_B G)\]
也就是在 $S_W$ 的零空间中最大化类间散度。JMLR 论文指出,NLDA 正是通过在类内散度矩阵的零空间中最大化类间距离来隐式避免奇异性。
2.7.2 NLDA 推导流程
由于直接求 $S_W$ 的零空间可能很大,常先去掉 $S_T$ 的零空间。
定义:
\[S_T=S_B+S_W\]
做 SVD:
\[H_T=U\Sigma V^T\]
于是:
\[S_T=H_T H_T^T=U\Sigma\Sigma^T U^T\]
设 $U_1$ 对应非零奇异值,则投影到 $U_1$ 空间:
\[\widetilde{S}_B=U_1^T S_B U_1\]
\[\widetilde{S}_W=U_1^T S_W U_1\]
然后找:
\[W\in \operatorname{Null}(\widetilde{S}_W)\]
即:
\[W^T \widetilde{S}_W W=0\]
再在这个零空间中最大化:
\[\max_M \operatorname{tr}(M^T W^T\widetilde{S}_B W M)\]
最终:
\[G=U_1 W M\]
JMLR 论文中给出了 NLDA 算法:先对 $H_T$ 做 reduced SVD,形成 $\widetilde{S}_B,\widetilde{S}_W$,再计算 $\widetilde{S}_W$ 的零空间,最后在该零空间中取 $W^T\widetilde{S}_B W$ 的主特征向量。
2.8. OLDA:Orthogonal LDA
2.8.1 OLDA 的目标
OLDA 希望得到正交判别向量:
\[G^T G=I\]
它的优化形式为:
\[G = \arg\max_{G^TG=I} \operatorname{tr}\left((G^T S_T G)^+G^T S_B G\right)\]
其中 $(\cdot)^+$ 是 Moore–Penrose 伪逆。
OLDA 的思想是通过同时对角化 $S_B,S_W,S_T$,在避免奇异问题的同时获得正交投影方向。JMLR 论文说明,OLDA 可以分解为三步:去掉 $S_T$ 零空间、执行 classical ULDA、再做正交化。
2.8.2 OLDA 推导流程
仍从:
\[H_T=U\Sigma V^T\]
得到 $U_1,\Sigma_T$。
构造:
\[B=\Sigma_T^{-1}U_1^T H_B\]
对 $B$ 做 SVD:
\[B=P\widetilde{\Sigma}Q^T\]
构造:
\[X_q=U_1\Sigma_T^{-1}P_q\]
其中 $q=\operatorname{rank}(S_B)$。
然后做 QR 分解:
\[X_q=QR\]
最终:
\[G=Q\]
即 $Q$ 是 OLDA 的正交判别投影矩阵。JMLR 论文中 Algorithm 2 正是这个流程。
2.8.3 NLDA 与 OLDA 的等价条件
论文给出条件:
\[C1:\quad \operatorname{rank}(S_T) = \operatorname{rank}(S_B) + \operatorname{rank}(S_W)\]
在该条件成立时:
\[\text{NLDA} \equiv \text{OLDA}\]
也就是说,虽然 NLDA 从 $S_W$ 零空间角度出发,OLDA 从正交化和同时对角化角度出发,但在高维小样本数据中,它们常得到等价的判别子空间。JMLR 论文的主结论就是在该温和条件下 NLDA 与 OLDA 等价,并据此提出更高效的 iNLDA。
2.9 LPP 与 MFA:从全局结构到局部结构
9.1 PCA/LDA 的不足
PCA 和 LDA 都偏全局:
- PCA 保留全局方差;
- LDA 保留全局类间/类内散度。
但很多图像数据在高维空间里具有局部流形结构。LPP 和 MFA 的思想是用图来描述局部邻域关系。
2.9.2 图嵌入统一框架
定义图权重矩阵:
\[W\]
度矩阵:
\[D_{ii}=\sum_j W_{ij}\]
图拉普拉斯矩阵:
\[L=D-W\]
经典图嵌入目标:
\[\min_U \operatorname{tr}(U^T X L_w X^T U)\]
约束:
\[\operatorname{tr}(U^T X L_b X^T U)=\text{const}\]
对应广义特征值问题:
\[XL_wX^T U = \lambda XL_bX^T U\]
RI 维度约简论文指出,PCA、LDA、LPP、MFA 都可以放入图嵌入框架,但该框架通常使用 $L_2$ 或 Frobenius 范数,因此容易受异常值和图像变化影响。
2.9.3 LPP
LPP 目标是保持近邻点在低维空间中仍然接近:
\[\min_U \sum_{i,j}|U^Tx_i-U^Tx_j|^2 W_{ij}\]
展开:
\[\sum_{i,j}|U^T(x_i-x_j)|^2W_{ij} = 2\operatorname{tr}(U^T X L X^T U)\]
约束常写为:
\[U^T X D X^T U=I\]
因此得到:
\[XLX^TU=\lambda XDX^TU\]
2.9.4 MFA
MFA 同时构建两类图:
- 类内 compactness graph:同类近邻应靠近;
- 类间 penalty graph:不同类边界邻居应远离。
目标可写为:
\[\min_U \frac{\operatorname{tr}(U^T X L_c X^T U)}{\operatorname{tr}(U^T X L_p X^T U)}\]
其中:
- $L_c$:类内紧致图;
- $L_p$:类间惩罚图。
对应广义特征值问题:
\[XL_cX^TU=\lambda XL_pX^TU\]
2.10RI $(L_{2,1})$ 鲁棒降维
2.10.1 为什么引入 $L_{2,1}$ 范数
传统 PCA/LDA/LPP/MFA 多用 Frobenius 范数:
\[\|A\|_F = \sqrt{\sum_i\sum_j a_{ij}^2}\]
平方项会放大异常值。
RI 论文定义 $L_{2,1}$ 范数为:
\[\|A\|_{2,1} = \sum_i \|A_i\|_2\]
其中 $A_i$ 是第 $i$ 行。该范数没有整体平方放大,并满足旋转不变性:
\[\|AR\|_{2,1}=\|A\|_{2,1}\]
其中 $R$ 为旋转矩阵。论文指出,$L_{2,1}$ 的鲁棒性来自其没有平方操作,并据此提出 RI-PCA、RI-LDA、RI-LPP、RI-MFA。
2.10.2 $L_{2,1}$ 到加权二次型的推导
考虑:
\[\|X^T U\|_{2,1} = \sum_i \|x_i^T U\|_2\]
为了便于求解,使用迭代加权形式。对每一项:
\[\|x_i^T U\|_2 \approx \frac{\|x_i^TU\|_2^2}{2\|x_i^T U^{(t)}\|_2}+\text{const}\]
因此定义权重:
\[D_{ii}^{(t)} = \frac{1}{2\|x_i^TU^{(t)}\|_2}\]
于是:
\[\sum_i \|x_i^T U\|_2 \approx \operatorname{tr}(U^T X D^{(t)} X^T U)\]
这就是 RI 系列方法的核心:把非光滑的 $L_{2,1}$ 优化转化为一系列加权二次型特征值问题。
2.10.3 RI-PCA
RI-PCA 用 $L_{2,1}$ 度量总体散度:
\[\sum_{i=1}^{N} \|(x_i-\bar{x})^T U\|_2 = \|X_{Rt}^T U\|_{2,1}\]
其中:
\[X_{Rt}=[x_1-\bar{x},\dots,x_N-\bar{x}]\]
加权矩阵:
\[D_{Rt,ii} = \frac{1}{2\|(x_i-\bar{x})^T U\|_2}\]
于是 RI 总散度:
\[S_{Rt}=X_{Rt}D_{Rt}X_{Rt}^T\]
RI-PCA 求:
\[\min_U \operatorname{tr}(U^TS_{Rt}U) \quad \text{s.t.}\quad U^TU=I\]
对应:
\[X_{Rt}D_{Rt}X_{Rt}^TU=\lambda U\]
由于 $D_{Rt}$ 依赖于 $U$,所以需要迭代更新。RI 论文中给出了 RI-PCA 的目标、对应特征方程和迭代求解方式。
2.10.4 RI-LDA
RI-LDA 定义 RI 类间散度:
\[S_{Rb}=X_{Rb}D_{Rb}X_{Rb}^T\]
其中:
\[X_{Rb}=[N_1(\bar{x}_1-\bar{x}),\dots,N_c(\bar{x}_c-\bar{x})]\]
权重:
\[D_{Rb,ii} = \frac{1}{2\|N_i(\bar{x}_i-\bar{x})^TU\|_2}\]
RI 类内散度:
\[S_{Rw}=X_{Rw}D_{Rw}X_{Rw}^T\]
目标:
\[\min_{U^TU=I} \frac{\operatorname{tr}(U^T S_{Rw}U)}{\operatorname{tr}(U^T S_{Rb}U)}\]
对应特征值问题:
\[S_{Rb}^{-1}S_{Rw}U=\lambda U\]
取较小特征值对应方向。RI 论文中明确给出 RILDA 的类间、类内 $L_{2,1}$ 散度定义,以及由此得到的特征值求解形式。
2.10.5 RI-LPP 与 RI-MFA
RI-LPP 把 LPP 中的平方距离:
\[\sum_{i,j}\|U^T(x_i-x_j)\|_2^2 W_{ij}\]
替换为:
\[\sum_{i,j}\|U^T(x_i-x_j)\|_2 W_{ij}\]
然后转化为加权二次型:
\[\operatorname{tr}(U^T X_R G_{Rl}D_{Rl}G_{Rl}X_R^T U)\]
目标:
\[\min_{U^TU=I} \frac{\operatorname{tr}(U^T S_{Rl}U)}{\operatorname{tr}(U^T S_{Rd}U)}\]
对应:
\[S_{Rd}^{-1}S_{Rl}U=\lambda U\]
RI-MFA 类似,只是把图换成:
- 类内 compactness 图;
- 类间 penalty 图。
目标:
\[\min_{U^TU=I} \frac{\operatorname{tr}(U^T S_{Rc}U)}{\operatorname{tr}(U^T S_{Rp}U)}\]
对应:
\[S_{Rp}^{-1}S_{Rc}U=\lambda U\]
RI 论文把 RIPCA、RILDA、RILPP、RIMFA 统一成一个 RI 子空间学习框架,并指出这些方法本质上是对应传统方法的重加权版本。
2.11 一个统一视角
这些方法可以统一理解为:
\[\min_U \frac{\text{不希望保留的变化}}{\text{希望保留的变化}}\]
或:
\[\max_U \frac{\text{希望保留的变化}}{\text{不希望保留的变化}}\]
对应关系:
| 方法 |
希望保留 |
希望压制 |
| PCA |
总方差 |
无 |
| LDA |
类间散度 $S_B$ |
类内散度 $S_W$ |
| MMC |
$S_B-S_W$ 为正的方向 |
$S_B-S_W$ 为负的方向 |
| NLDA |
零类内散度方向上的类间散度 |
类内散度 |
| OLDA |
正交判别方向 |
冗余/奇异性 |
| LPP |
局部邻域结构 |
局部结构破坏 |
| MFA |
类间边界分离 |
类内邻域分散 |
| RI 方法 |
鲁棒散度 |
异常值、图像变化 |
2.12 建议掌握的推导重点
按重要性排序:
1. PCA 推导
\[\max u^TS_Tu,\ u^Tu=1 \Rightarrow S_Tu=\lambda u\]
2. LDA 推导
\[\max \frac{u^TS_Bu}{u^TS_Wu} \Rightarrow S_Bu=\lambda S_Wu\]
3. Fisherfaces 小样本处理
\[U_{\text{opt}}^T=U_{\text{LDA}}^TU_{\text{PCA}}^T\]
4. MMC 推导
\[\text{margin} = \text{类间距离} - \text{类内扩散} \Rightarrow J(U)=\operatorname{tr}(U^T(S_B-S_W)U)\]
5. NLDA 推导
\[\max_{G^TS_WG=0}\operatorname{tr}(G^TS_BG)\]
6. OLDA 推导
\[\max_{G^TG=I}\operatorname{tr}((G^TS_TG)^+G^TS_BG)\]
7. RI $L_{2,1}$ 推导
\[\|X^TU\|_{2,1} = \sum_i\|x_i^TU\|_2 \approx \operatorname{tr}(U^TXDX^TU)\]
2.13 一句话总结
这组文献的主线是:PCA 从无监督最大方差开始,但不够判别;LDA/Fisherfaces 引入类别散度,但遇到小样本奇异;MMC、NLDA、OLDA分别从差值准则、零空间、正交约束解决奇异性;LPP/MFA进一步引入局部图结构;RI 系列再用 $L_{2,1}$ 范数把这些方法鲁棒化。
三、回归
0. 总体框架
这几篇论文可以分成三类:
| 主题 |
对应论文 |
核心思想 |
| 线性回归分类 |
Linear Regression for Face Recognition |
每一类样本张成一个子空间,测试样本用每个类的训练样本重构,残差最小者为类别 |
| 稀疏/鲁棒特征选择 |
Efficient and Robust Feature Selection via Joint $\ell_{2,1}$-Norms Minimization |
用 $\ell_{2,1}$ 损失增强抗异常点能力,用 $\ell_{2,1}$ 正则产生行稀疏,从而选特征 |
| 无监督判别特征选择 |
$\ell_{2,1}$-Norm Regularized Discriminative Feature Selection for Unsupervised Learning |
无标签时假设伪标签可由线性分类器预测,结合局部判别信息与 $\ell_{2,1}$ 正则 |
| 谱回归/稀疏子空间学习 |
Spectral Regression: A Unified Approach for Sparse Subspace Learning |
先做图嵌入求响应 $y$,再用回归求投影方向 $a$,可自然加入 Lasso/Elastic Net 稀疏正则 |
LRC 论文明确把人脸识别建模为线性回归分类,并用最小重构误差决策;谱回归论文则把 LDA、LPP、NPE 等谱方法统一成先谱嵌入、后回归的两步框架;两篇 $\ell_{2,1}$ 论文进一步把回归目标加上行稀疏正则,用于特征选择。
3.1 线性回归分类 LRC:从最小二乘到最近子空间
3.1.1 基本假设
第 $i$ 类有 $p_i$ 张训练图像,每张图像拉直为 $q$ 维向量:
\[w_i^{(m)} \in \mathbb{R}^{q},\quad m=1,\dots,p_i\]
第 $i$ 类训练样本按列堆叠:
\[X_i = [w_i^{(1)}, w_i^{(2)}, \dots, w_i^{(p_i)}] \in \mathbb{R}^{q \times p_i}\]
LRC 核心假设:同一类样本近似落在同一个线性子空间,若测试样本 $y$ 属于第 $i$ 类,则:
\[y \approx X_i \alpha_i\]
$\alpha_i \in \mathbb{R}^{p_i}$ 为回归系数,本质是最近子空间分类。
3.1.2 最小二乘推导
对第 $i$ 类求解:
\[\hat{\alpha}_i = \arg\min_{\alpha_i} \|y - X_i\alpha_i\|_2^2\]
目标函数展开:
\[J(\alpha_i) = (y - X_i\alpha_i)^T(y - X_i\alpha_i) = y^T y - 2\alpha_i^T X_i^T y + \alpha_i^T X_i^T X_i \alpha_i\]
对 $\alpha_i$ 求导:
\[\frac{\partial J}{\partial \alpha_i} = -2X_i^T y + 2X_i^T X_i \alpha_i\]
令导数为 0:
\[X_i^T X_i \alpha_i = X_i^T y\]
若 $X_i^T X_i$ 可逆:
\[\hat{\alpha}_i = (X_i^T X_i)^{-1}X_i^T y\]
3.1.3 投影矩阵与重构误差
第 $i$ 类重构样本:
\[\hat{y}_i = X_i \hat{\alpha}_i\]
代入最小二乘解:
\[\hat{y}_i = X_i(X_i^T X_i)^{-1}X_i^T y\]
定义帽子矩阵:
\[H_i = X_i(X_i^T X_i)^{-1}X_i^T\]
则
\[\hat{y}_i = H_i y\]
分类残差:
\[d_i(y) = \|y - \hat{y}_i\|_2\]
决策规则:
\[\hat{c} = \arg\min_i d_i(y)\]
3.1.4 模块化 LRC 与遮挡处理
图像分 $M$ 个局部块,第 $n$ 块第 $i$ 类子空间:
\[U_i^{(n)} = \big[w_i^{(1)}(n), w_i^{(2)}(n), \dots, w_i^{(p_i)}(n)\big]\]
测试图像第 $n$ 块:$y^{(n)}$,最小二乘解:
\[\hat{\alpha}_i^{(n)} = \big((U_i^{(n)})^T U_i^{(n)}\big)^{-1}(U_i^{(n)})^T y^{(n)}\]
局部重构与残差:
\[\hat{y}_i^{(n)} = U_i^{(n)}\hat{\alpha}_i^{(n)},\quad d_i(y^{(n)}) = \|y^{(n)} - \hat{y}_i^{(n)}\|_2\]
局部块决策:
\[j^{(n)} = \arg\min_i d_i(y^{(n)})\]
3.2 $\ell_{2,1}$-范数:为什么能做特征选择?
3.2.1 定义
矩阵 $M \in \mathbb{R}^{n \times m}$,第 $i$ 行 $m_i$:
\[\|M\|_{2,1} = \sum_{i=1}^{n} \|m_i\|_2 = \sum_{i=1}^{n} \sqrt{\sum_{j=1}^{m} M_{ij}^2}\]
结构特点:
- 行内 $\ell_2$:整行视作整体;
- 行间 $\ell_1$:诱导行稀疏。
若 $W \in \mathbb{R}^{d \times c}$,每行对应一个原始特征:
\[\|W\|_{2,1} = \sum_{j=1}^{d} \|w_j\|_2\]
行范数趋近 0 则对应特征可剔除。
3.3 RFS:联合 $\ell_{2,1}$ 最小化的鲁棒特征选择
3.3.1 从普通最小二乘开始
\[X = [x_1, x_2, \dots, x_n] \in \mathbb{R}^{d \times n},\quad Y = [y_1, y_2, \dots, y_n]^T \in \mathbb{R}^{n \times c}\]
线性预测:
\[\hat{Y} = X^T W\]
普通最小二乘:
\[\min_W \|X^T W - Y\|_F^2 = \sum_{i=1}^{n} \|W^T x_i - y_i\|_2^2\]
3.3.2 鲁棒损失:残差不平方
RFS 改用样本残差 $\ell_2$ 求和:
\[\sum_{i=1}^{n} \|W^T x_i - y_i\|_2 = \|X^T W - Y\|_{2,1}\]
3.3.3 加入行稀疏正则
最终目标:
\[\min_W J(W) = \|X^T W - Y\|_{2,1} + \gamma \|W\|_{2,1}\]
3.3.4 约束形式推导
令误差矩阵 $E$:
\[E = \frac{Y - X^T W}{\gamma} \;\Rightarrow\; X^T W + \gamma E = Y\]
等价优化:
\[\min_{W,E} \|W\|_{2,1} + \|E\|_{2,1} \quad \text{s.t.} \quad X^T W + \gamma E = Y\]
拼接变量与系数矩阵:
\[U = \begin{bmatrix} W \\ E \end{bmatrix},\quad A = [X^T,\ \gamma I]\]
约束化为 $AU=Y$,目标:
\[\min_U \|U\|_{2,1} \quad \text{s.t.} \quad AU = Y\]
3.3.5 迭代重加权解法推导
拉格朗日函数:
\[\mathcal{L}(U) = \|U\|_{2,1} + \operatorname{Tr}\big[\Lambda^T(AU - Y)\big]\]
$\ell_{2,1}$ 范数梯度:
\[\frac{\partial \|U\|_{2,1}}{\partial U} = 2DU\]
$D$ 为对角阵:
\[D_{ii} = \frac{1}{2\|u_i\|_2}\]
极值条件:
\[2DU - A^T\Lambda = 0 \;\Rightarrow\; U = \frac{1}{2}D^{-1}A^T\Lambda\]
代入约束 $AU=Y$:
\[\Lambda = 2(AD^{-1}A^T)^{-1}Y\]
回代得闭式:
\[U = D^{-1}A^T(AD^{-1}A^T)^{-1}Y\]
迭代更新:
\[U_{t+1} = D_t^{-1}A^T(AD_t^{-1}A^T)^{-1}Y,\quad (D_{t+1})_{ii} = \frac{1}{2\|(u_{t+1})_i\|_2}\]
3.4 UDFS:无监督场景下的判别特征选择
3.4.1 局部判别思想
样本局部邻域 $N_k(x_i)$,局部数据矩阵:
\[X_i = [x_i, x_{i1}, \dots, x_{ik}]\]
局部中心化矩阵:
\[H_{k+1} = I - \frac{1}{k+1}\mathbf{1}\mathbf{1}^T\]
中心化数据:
\[\tilde{X}_i = X_i H_{k+1}\]
局部散度:
\[S_t^{(i)} = \tilde{X}_i \tilde{X}_i^T,\quad S_b^{(i)} = \tilde{X}_i G_{(i)}G_{(i)}^T \tilde{X}_i^T\]
无监督伪标签:
\[G = X^T W,\quad G_{(i)} = S_i^T X^T W\]
3.4.2 局部判别分数推导
\[DS_i = \operatorname{Tr}\Big[(S_t^{(i)} + \lambda I)^{-1}S_b^{(i)}\Big]\]
代入散度与伪标签,利用迹循环性质化简得:
\[DS_i = \operatorname{Tr}\Big[ W^T X S_i \tilde{X}_i^T (\tilde{X}_i\tilde{X}_i^T+\lambda I)^{-1} \tilde{X}_i S_i^T X^T W \Big]\]
3.4.3 UDFS 目标函数推导
最小化形式:
\[\min_{W^T W=I} \sum_{i=1}^{n} \operatorname{Tr}\big(W^T X S_i H_{k+1}S_i^T X^T W\big) - DS_i + \gamma \|W\|_{2,1}\]
化简为统一矩阵形式:
\[\min_{W^T W=I} \operatorname{Tr}(W^T M W) + \gamma \|W\|_{2,1}\]
其中
\[M = X\left[ \sum_{i=1}^{n} S_iH_{k+1} (\tilde{X}_i^T\tilde{X}_i+\lambda I)^{-1} H_{k+1}S_i^T \right]X^T\]
3.4.4 UDFS 的优化
$\ell_{2,1}$ 重加权近似:
\[\|W\|_{2,1} \approx \operatorname{Tr}(W^T D W),\quad D_{jj} = \frac{1}{2\|w_j\|_2}\]
每轮优化:
\[\min_{W^T W=I} \operatorname{Tr}\big[W^T(M+\gamma D)W\big]\]
迭代步骤:
\[P_t = M + \gamma D_t,\quad W_t = \text{eig}_{\min\,c}(P_t),\quad (D_{t+1})_{jj} = \frac{1}{2\|(w_t)_j\|_2}\]
3.5 谱回归 SR/USSL:把谱嵌入转化为回归
3.5.1 图嵌入目标
图权重 $W$、度矩阵 $D_{ii}=\sum_j W_{ij}$、拉普拉斯 $L=D-W$。
一维嵌入 $y$:
\[\min_y \sum_{i,j}(y_i-y_j)^2 W_{ij} = \min_y 2y^T L y\]
约束:
\[\min_y y^T L y \quad \text{s.t.} \quad y^T D y = 1\]
等价广义特征值:
\[Wy = \lambda Dy\]
3.5.2 线性外推:从 $y$ 到投影方向 $a$
线性映射:$y_i = a^T x_i$,整体
\[y = X^T a\]
代入得高维广义特征问题:
\[X W X^T a = \lambda X D X^T a\]
3.5.3 谱回归核心定理
两步分解:
- 谱求解:$\boldsymbol{Wy = \lambda Dy}$
- 回归拟合:
\[a = \arg\min_a \sum_{i=1}^{m}(a^T x_i - y_i)^2\]
3.5.4 加入稀疏正则
普通回归:
\[a = \arg\min_a \sum_{i=1}^{m}(a^T x_i - y_i)^2\]
Ridge:
\[a = \arg\min_a \sum_{i=1}^{m}(a^T x_i - y_i)^2 + \alpha \sum_{j=1}^{n}a_j^2\]
Lasso:
\[a = \arg\min_a \sum_{i=1}^{m}(a^T x_i - y_i)^2 + \beta \sum_{j=1}^{n}|a_j|\]
Elastic Net:
\[a = \arg\min_a \sum_{i=1}^{m}(a^T x_i - y_i)^2 + \alpha \|a\|_2^2 + \beta \|a\|_1\]
3.6 四篇论文之间的关系
主线逻辑:
\[\text{子空间/图结构} \Rightarrow \text{回归形式} \Rightarrow \text{正则化} \Rightarrow \text{分类/特征选择}\]
- LRC:$y \approx X_i\alpha_i$,靠重构残差分类;
- Spectral Regression:$X^T a \approx y$,谱嵌入+回归统一谱方法;
- RFS:$X^T W \approx Y$,$\ell_{2,1}$ 损失抗噪、$\ell_{2,1}$ 正则选特征;
- UDFS:$G = X^T W$,无监督构造伪标签,结合局部判别与 $\ell_{2,1}$ 稀疏选特征。
3.7 核心公式汇总
LRC
\[\hat{\alpha}_i = (X_i^T X_i)^{-1}X_i^T y,\quad \hat{y}_i = X_i\hat{\alpha}_i,\quad d_i(y)=\|y-\hat{y}_i\|_2,\quad \hat{c}=\arg\min_i d_i(y)\]
$\ell_{2,1}$-范数
\[\|W\|_{2,1} = \sum_{j=1}^{d}\|w_j\|_2\]
RFS
\[\min_W \|X^T W - Y\|_{2,1} + \gamma\|W\|_{2,1},\quad \min_U \|U\|_{2,1}\;\text{s.t.}\;AU=Y\]
\[U_{t+1} = D_t^{-1}A^T(AD_t^{-1}A^T)^{-1}Y,\quad (D_{t+1})_{ii} = \frac{1}{2\|u_{t+1,i}\|_2}\]
UDFS
\[DS_i = \operatorname{Tr}\big[(S_t^{(i)}+\lambda I)^{-1}S_b^{(i)}\big],\quad G = X^T W\]
\[\min_{W^T W=I} \operatorname{Tr}(W^TMW) + \gamma\|W\|_{2,1}\]
Spectral Regression
\[Wy=\lambda Dy,\quad y=X^T a,\quad XWX^T a = \lambda XDX^T a\]
\[a=\arg\min_a\sum_i(a^T x_i-y_i)^2\]
3.8 一句话总结
把高维模式识别问题统一建模为线性回归/谱回归;分类依托子空间重构残差,特征选择依靠 $\ell_{2,1}/\ell_1$ 正则诱导稀疏置零无用特征;无监督场景借助图结构与局部判别构造可回归的伪标签,全程以回归+残差+稀疏正则+谱图结构为统一框架。
]]>

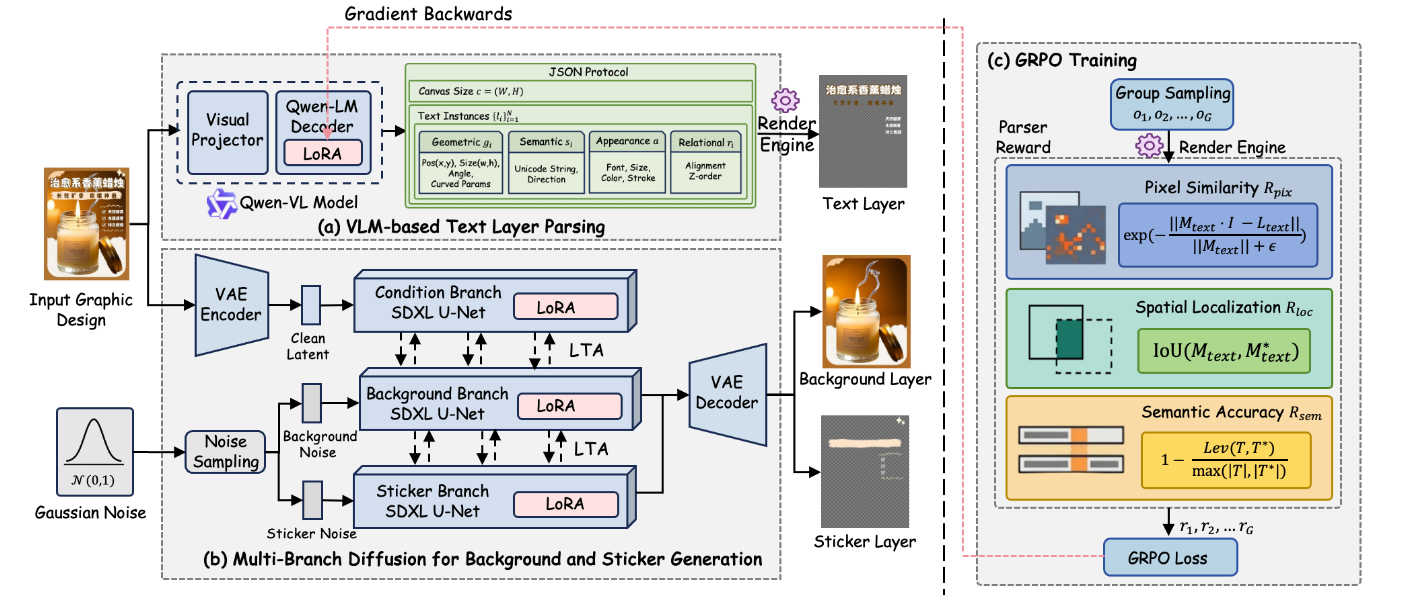
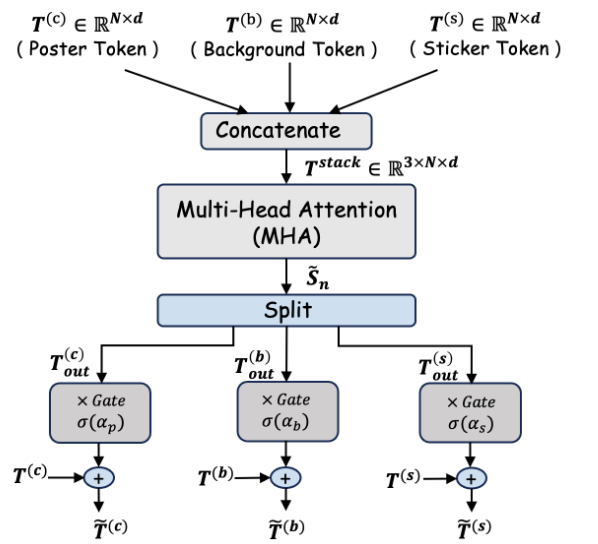 假设三个分支在同一空间位置都有 token:
假设三个分支在同一空间位置都有 token: